SALSA Recommendations
General Dynamics for SALSA
NOTE: For the purposes of this documentation, a viseme is a representation of a visual configuration. This does not imply that SALSA is capable of analyzing audio and interpreting actual phoneme sounds and subsequently displaying the appropriate phoneme. It is not a phoneme mapping solution and cannot, for example, equate a 'v' (as in 'very') sound to a 'v' phoneme representation. We consider SALSA's triggered configurations as 'visemes' simply as a description of the underlying components.
Since SALSA analysis does not detect specific phonemes, it relies on its viseme configurations to produce adequate dynamic animation changes. Progressive amplitude analysis operates on the principle that larger amplitudes produce more dynamic energy, which in turn, requires bigger mouth shapes to produce said dynamic energy. Of course, this is not a hard and fast rule and is the reason SALSA does not produce Pixar-perfect lipsync results. However, it utilizes many additional techniques to create acceptable perceived accuracy. Viseme dynamics is one of those techniques and is implemented in the viseme configuration -- regardless of the controller type. Therefore, use of shapes producing progressively larger, but dynamically different shapes, is key.

In the diagram above, each 'recommended' progressive shape is functionally larger, but also quite different in shape definition, producing good lip movement over the spectrum. If the shapes are configured in a simple progression of size (as in the not recommended example), the overall dynamic movement will be close to zero. This creates a simple, singularly opening mouth -- we like to call jaw-chomping. You can achieve this sort of look with a single shape and Advanced Dynamics enabled. If this is the look you are going for, AWESOME! SALSA can do that and the configuration is very simple. However, if you want more realistic or dynamic lip-synchronization, SALSA is also the tool of choice.
SALSA Configuration
As mentioned previously, SALSA configuration supports a wide variety of controller types. For 3D character models, blendshapes are probably the easiest to implement; however, bones can be used to equal effect. It simply comes down to what system you prefer to use. If SALSA is being configured for a 2D character, the same general concepts apply, the controller is just different. You may determine you prefer a smooth, multi-frame animation, or a stuttery, single-frame transition.
Whatever the implementation, animation controller, or style, SALSA has very loose requirements, mainly based on desired look-and-feel. SALSA v1 utilized three shapes to perform realtime lip-sync and did so to great effect. The same capability exists in SALSA v2. In fact, the minimum requirement is a single viseme configuration (one shape). But, that is not nearly as cool and exciting as it could be. Version 2 supports an unlimited number of viseme configurations, but there are practical limits and points of diminishing returns. Additionally, with the implementation of Advanced Dynamics, the amount of dynamic representation is greatly expanded regardless of the number of shapes implemented.
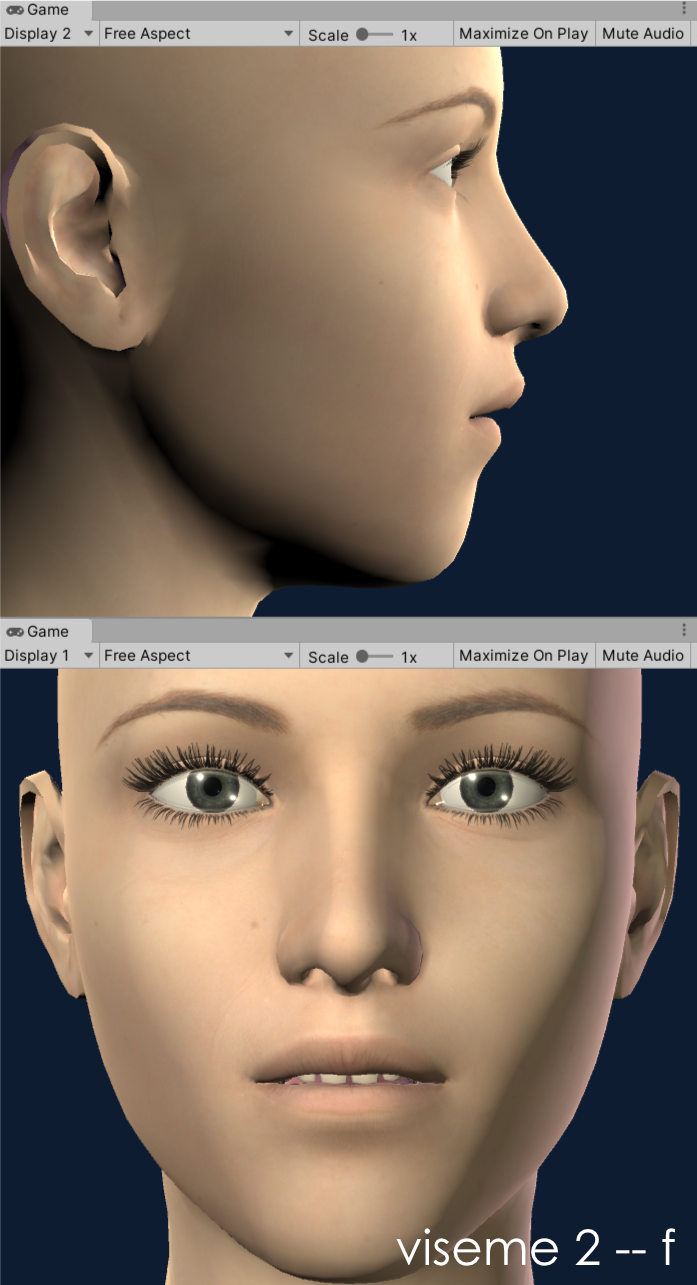
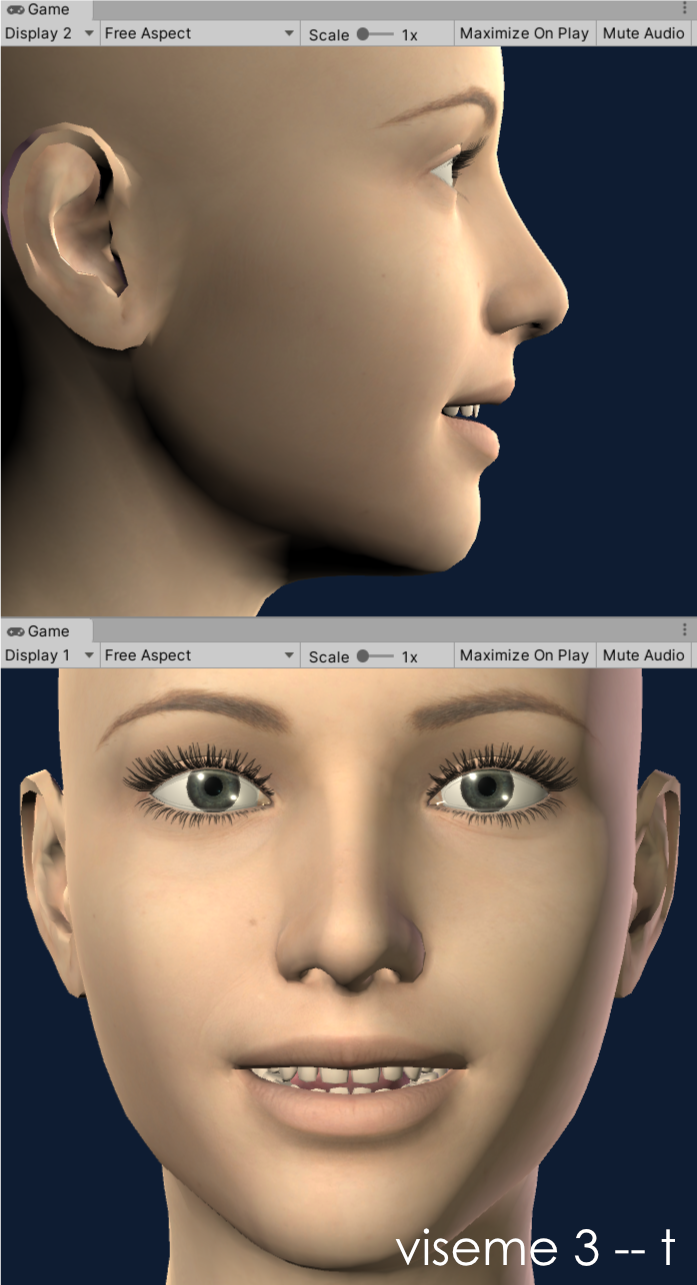
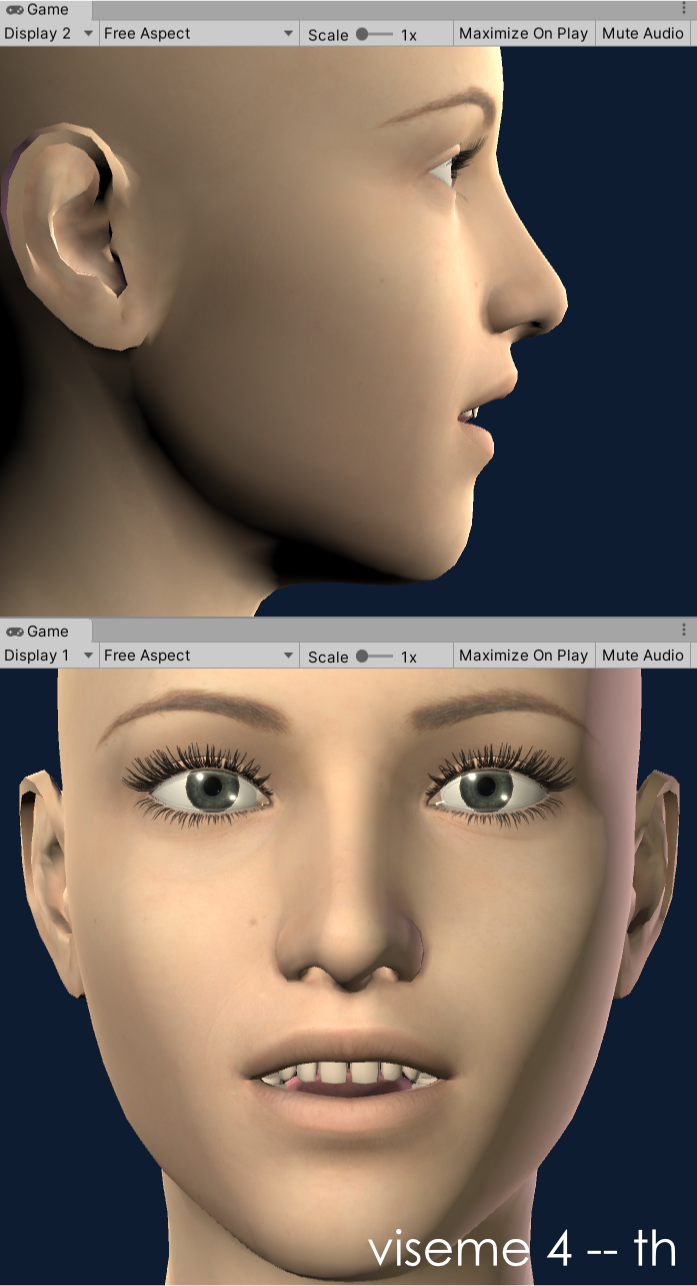
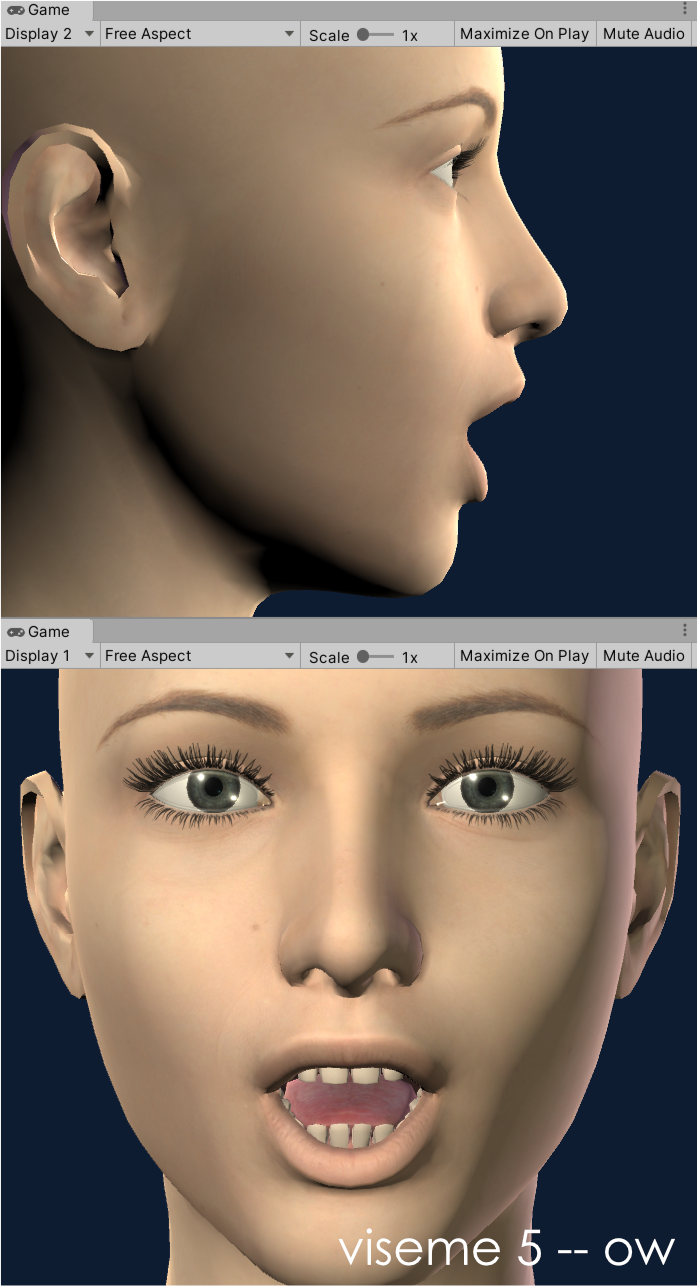
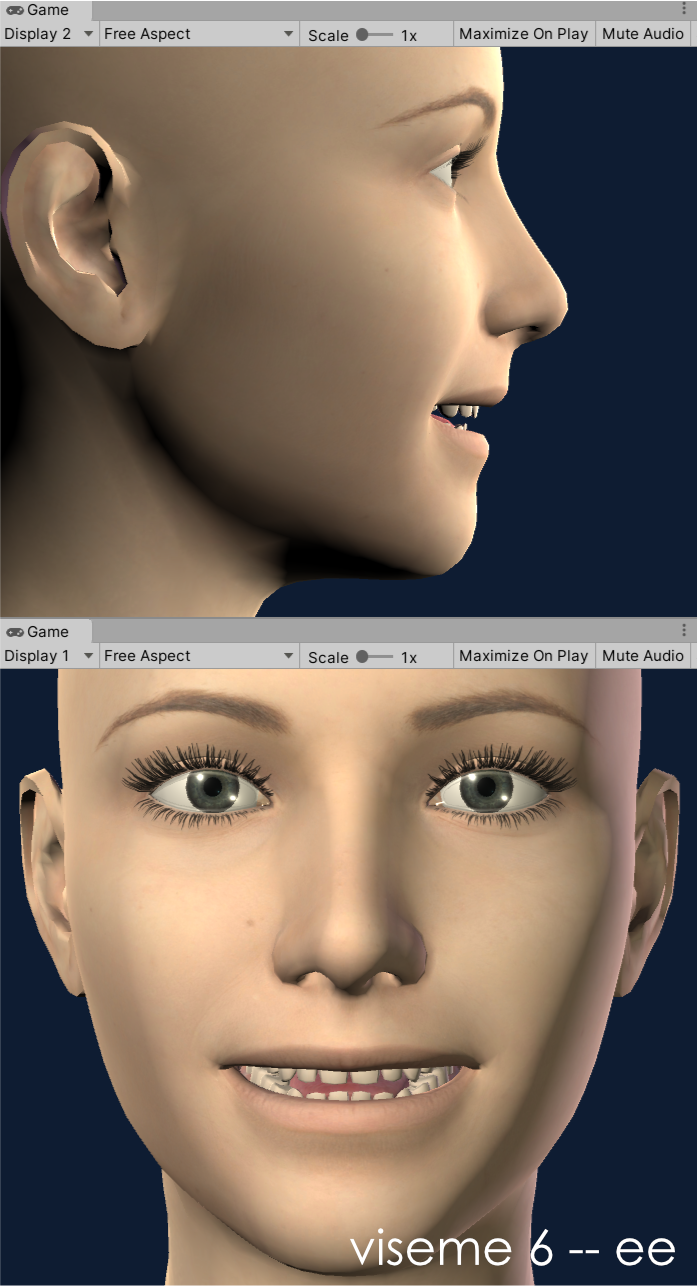
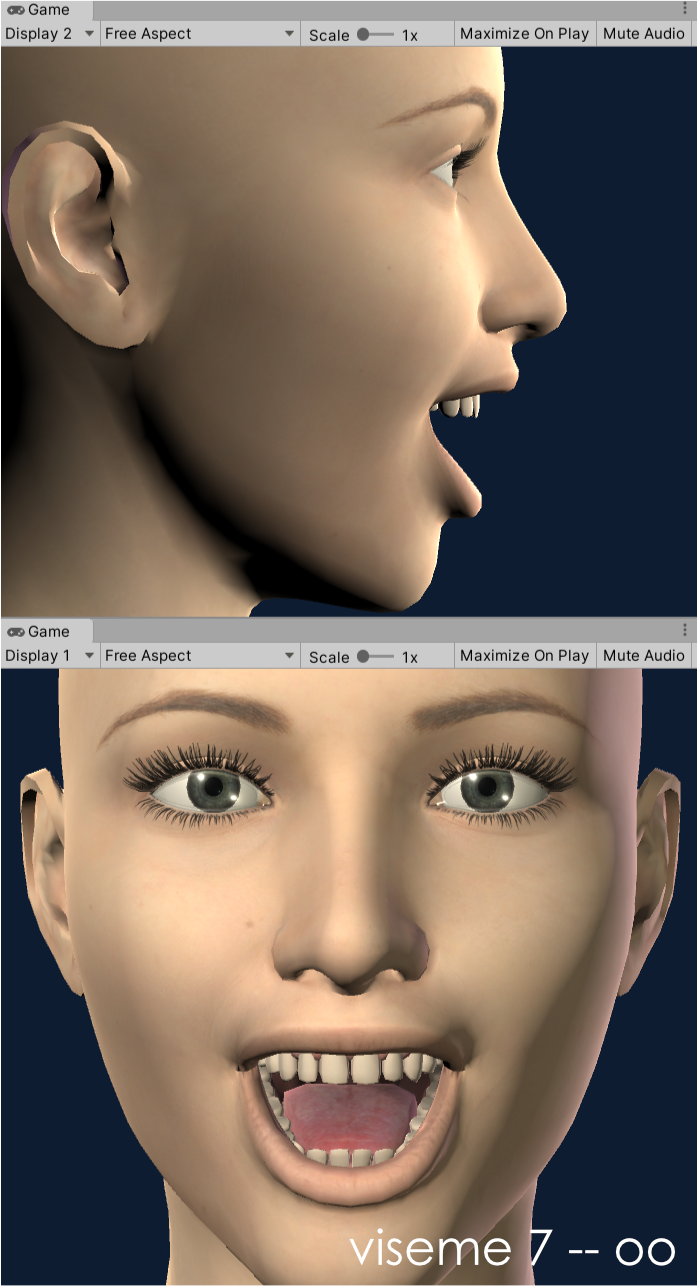
Our OneClick configurations (available on supported models) currently utilize seven shapes and this theoretical setup can be applied to 2D or 3D. The shapes we have chosen to implement are based on the phoneme visualisations for: w, f, t, th, ow, ee, oo (in that order). If you are looking closely, you might notice that this recommendation swaps the 'f' and 't' shapes we used to use. This was a recent change that I discovered I liked while working on the DAZ Gen8.1 model configuration. It is being implemented in the existing OneClicks at this time (3/2021) and should be available soon. For example, the OneClick configuration for the DAZ Gen8.1 standard female model is demonstrated in the following images:

Individual visemes:
viseme 1 - w
viseme 2 - f
viseme 3 - t
viseme 4 - th
viseme 5 - ow
viseme 6 - ee
viseme 7 - oo
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Of course, you are free to implement whatever scheme you wish. The above configuration is only a starting point and may, or may not meet your needs. You might want more or fewer visemes. Different visemes. Whatever you like. SALSA is flexible enough to meet your requirements.
If you are configuring your own custom model, you can match up to the viseme choices we have made for our OneClick solutions or you can come up with your own. There are really no right or wrong answers, it is all up to design preference. If you don't have any idea where or how to start, we recommend copying our OneClick implementation strategy for viseme definition and progressing from there.
EmoteR's Recommendations
There are no set blendshape requirements for EmoteR since it is an emote driver. It is purely based on your requirements. If you only need a happy-face emote that will randomly fire on your model, then that is your only requirement and you only need a single emote definition. If you would like to implement SALSA-triggered emphasis emotes you may want a wider variety of subtle shapes for a less twitchy look and feel. Our OneClick solutions only provide SALSA Emphasis Emote configurations. They are designed to be subtle and affect the portions of the face that normally animate while a person talks. Here are the representations we have implemented as closely as possible in our OneClicks:
- Exasperation (cheek puff, slight brow raise -- make it subtle)
- Soften (a smile and relaxed brows)
- BrowsUp (both brows raised)
- BrowUp (raise a single brow more than the other)
- Squint (eye and brow narrowing)
- Focus (eye narrowing)
- Flare (nose/nostril movement)
- Scrunch (nose/nostril movement, eye/brow narrowing)
Remember, Emphasis Emotes should be visible, but subtle. We recommend triggering emphasis emotes in the SALSA configuration at level 0.0f -- meaning they always trigger. And the EmoteR emphasis chance should be 100%. Audio analysis and timing will affect the amount or energy of the triggered emotes.
Eyes Recommendations
Eyes can use blendshapes to move the eyes; however, this is probably better implemented with bone rotations. Blendshape "rotations" are not optimal since the overall shape of the rotating object is actually deformed during the "rotation". Blinks however, do work well, even though they can be subject to the same deformation associated with "rotation" since they are closing around a typically round object.
The Eyes module in SALSA Suite v2 does have a new feature that is very cool but does have some requirements: Eyelid Tracking. To implement Eyelid Tracking, the model has to have independent control over top and bottom eyelids (also upper-only control). This allows the upper and lower eyelids to move independently in the upward or downward directions to subtly follow eye movement.
NOTE: not all OneClick implementations support Eyelid Tracking. Fuse, ACG, iClone, CC3 and UMA support Eyelid Tracking. Only UMA supports upper and lower tracking.